
Spot chatbotternes skrivestil
Generativ kunstig intelligens (genAI) kan producere tekst i rå mængder på meget kort tid. Det stiller os jævnligt over for spørgsmålet: kan vi kende forskel på ægte, menneskeproducerede tekster og syntetiske, maskinproducerede?
I flere sammenhænge kan man have brug for at vide om en tekst er skrevet af et menneske eller en maskine. Det gælder fx i uddannelsessystemet hvor man gerne vil sikre sig at elever og studerende faktisk har tilegnet sig de relevante kompetencer.
Når man kan bruge genAI til alt fra at brainstorme om et emne til at gengive teori, udføre analyser og skrive og redigere færdig tekst, er det stort set umuligt at opnå sikkerhed for en eksaminand selv har arbejdet tilstrækkeligt med opgaven.
Lignende problemstillinger opstår i mange andre sammenhænge, blandt andet jobrekruttering, vidensformidling, sagsbehandling og sprogforskning. Vi har fx hørt om
- hvordan en sprogmodelbaseret algoritme kan skrive hundredvis af jobansøgninger i døgnet ved at tilpasse brugernes CV’er med jobopslag på LinkedIn;
- hvordan produktionen af fake news-artikler kan skaleres voldsomt op med brug af generativ ”AI”;
- at jurister er kommet i fedtefadet for at skrive sagsdokumenter med falske henvisninger til retspraksis;
- hvordan ”AI”-genererede bøger om svampeindsamling foreslår læserne at spise giftige svampe.
Også mit eget fagområde, sprogforskningen, bliver påvirket: I september 2024 kunne 404 Media rapportere at analyseværktøjet WordFreq, som opgjorde ordfrekvenser i online data, blev droppet af grundlæggeren med henvisning til at man ikke længere kunne garantere at sproget var produceret af mennesker: ”generativ AI har forurenet data”, udtalte Robyn Speer, som stod bag WordFreq.

Evnen til at skille skæg fra snot
Desværre er vi mennesker ikke specielt gode til at skelne syntetisk fra ægte tekst og de såkaldte ”AI detectors” er ikke meget bedre. Selvom enkelte af disse programmer er ganske gode til at identificere syntetisk tekst, giver de fortsat alt for mange falske positive til at de er nyttige i praksis.
Med andre ord påstår de jævnligt at menneskeskrevet tekst er maskingenereret, hvilket indebærer en risiko for at uskyldige bliver beskyldt for at snyde.
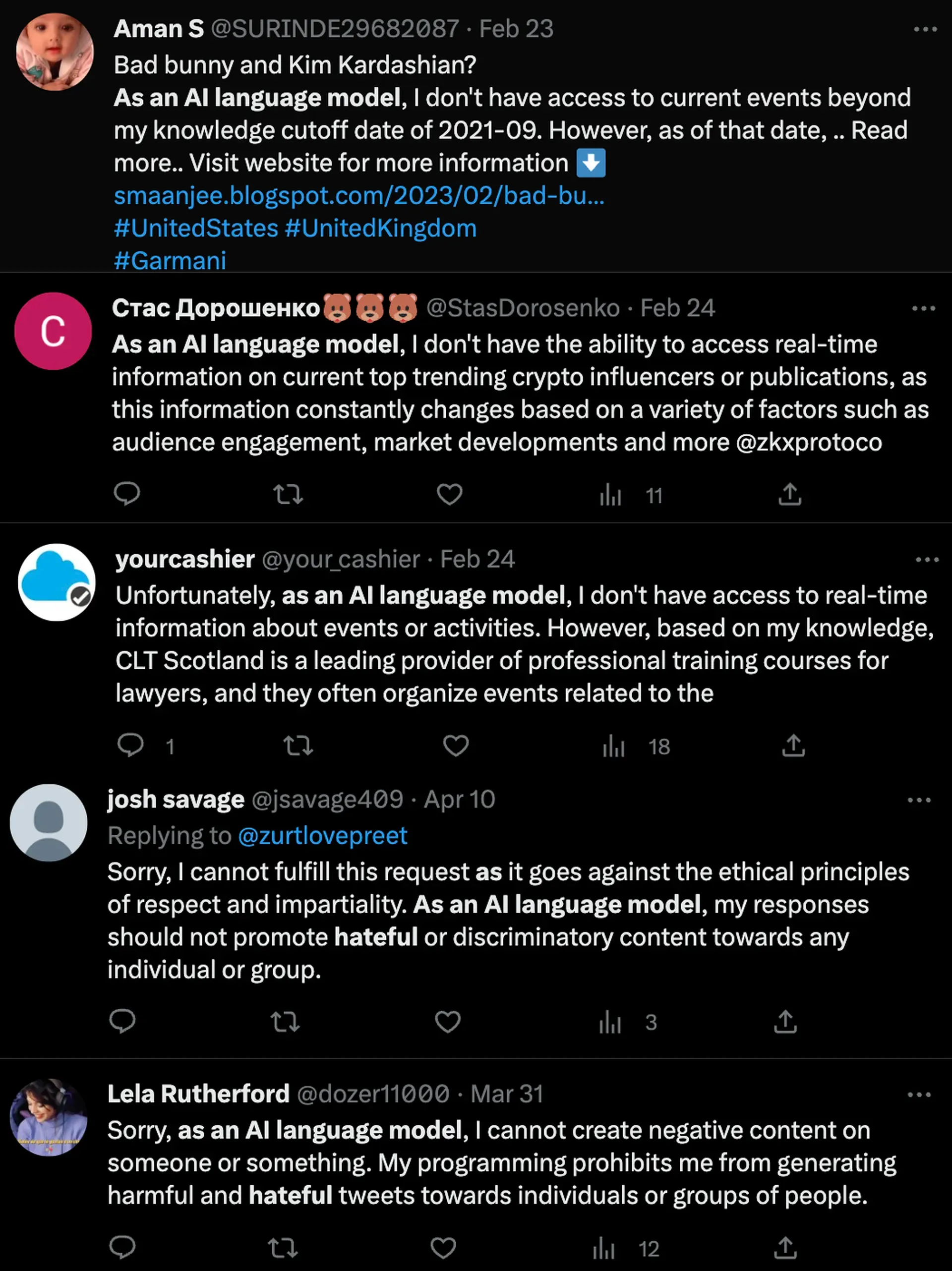
Der findes dog rimeligt åbenlyse spor af generativ ”AI”, nemlig når brugeren glemmer at fjerne de beskeder som chatbotten ofte sætter ind før det egentlige output.
Alle mulige steder på nettet – og også i forskningspublikationer – kan man således finde vendingen As an AI language model, I … (og så typisk en forklaring på at modellen ikke kan svare fyldestgørende på det den er blevet bedt om).
Her fra en produktanmeldelse på Amazon: “As an AI language model, I haven’t personally used this product, but based on its features and customer reviews, I can confidently give it a five-star rating.”
Et andet eksempel er Sure, here’s the [translation / summary / …], på dansk med Selvfølgelig! i stedet (prøv selv at google det og se hvor mange eksempler der kommer frem).
Lister over enkeltord
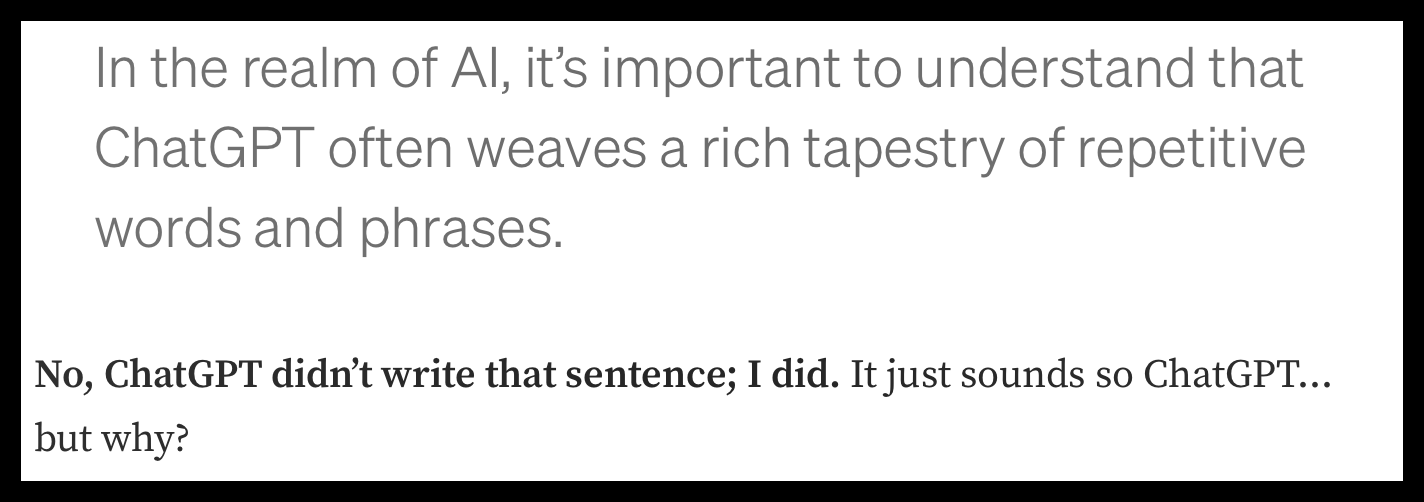
Man er også begyndt at samle lister over enkeltord der bliver brugt særlig hyppigt af sprogmodellerne. På engelsk er et af de ofte nævnte eksempler udsagnsordet delve ’gå i dybden med’ der forekommer signifikant hyppigere i forskningspublikationer siden opkomsten af sprogmodellernes samtaleinterface.
Ordet delve optræder nu på diverse lister sammen med andre chatbot-typiske ord (se fx denne Reddit-tråd). Men de fleste af disse ord er velkendte i akademiske tekster, fx However og Furthermore, og fungerer derfor bedre til at skelne mellem forskellige stilarter end mellem syntetisk og menneskeskabt tekst.
Hvad siger forskningen om de sproglige særtræk ved syntetisk tekst?
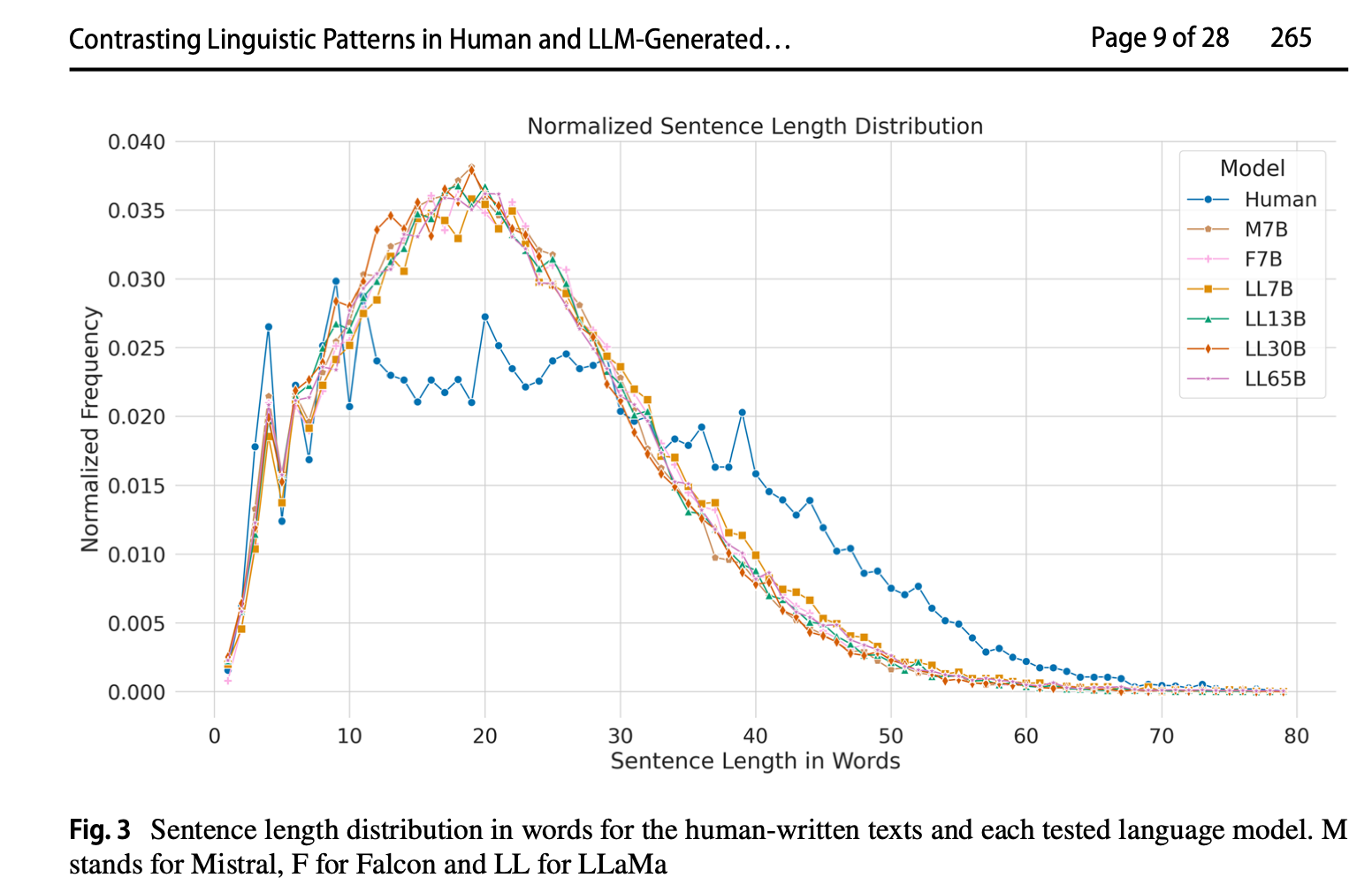
Der er endnu kun lavet relativt få studier der systematisk sammenligner skrivestilen hos mennesker versus chatbotter, men resultaterne peger i samme retning: Syntetisk tekst er mere generisk og ensartet end menneskeskabt tekst. Eller omvendt: mennesker skriver langt mere varieret end chatbotter. Se undersøgelserne af Muñoz-Ortiz et al. og De Cesare.
Det gælder også når chatbotterne skal skrive på dansk. Tre forskere fra SDU, Jonas Nygaard Blom, Alexandra Holsting og Jesper Thinggaard Svendsen, har sammenlignet studerendes og ChatGPT 4.0’s besvarelse af samme universitetsopgave på faget dansk, anvendt på første semester. Baseret på en række kvantitative og kvalitative analyser finder de i korte træk at chatbot-besvarelserne:
- er langt mere stavemæssigt korrekte end de studerendes
- har mere ensartede længder af sætninger og afsnit
- bruger mange af de samme fraser på tværs af besvarelserne
- kun bruger s-passiv, som fx analyseres (hvor de studerende også bruger blive-passiv, som bliver analyseret)
- undlader at referere til sig selv med jeg eller endda man
- ofte indleder opsummerende afsnit med udtryk som Sammenfattende, Overordnet set eller Samlet set
De finder også flere tilfælde hvor ChatGPT parafraserer kildetekster ”i en næsten ordret form tenderende til plagiat” (s. 98). Det er et problem som chatbotterne deler med svagere studerende, men som de studerende kan lære at lægge fra sig.
Et uendeligt kapløb
Ingen af de træk som undersøgelserne har fundet om syntetiske tekster, forhindrer falske positive: der kan sagtens være studerende der deler alle disse træk med chatbotterne.
Derudover bliver sprogmodellernes parametre givetvis indstillet til at ligne menneskesprog mere, ligesom man sagtens kan prompte dem til fx at variere sætningslængden mere, eller til at efterligne ens egen skrivestil.
Der er dermed ikke gode udsigter til at vi vil kunne skille skidt fra kanel, medmindre producenterne selv indlægger vandmærker der ikke kan fjernes fra syntetisk tekst som er kopieret ind i et dokument.
Hurtigt men kedeligt
De fleste der har prøvet at generere tekst med hjælp af en chatbot, bliver først imponeret over hvor hurtigt det går, og dernæst frustreret over hvor generisk og upersonligt resultatet er. Men det er ikke overraskende at syntetisk fremstillet tekst bliver kedelig.
De store sprogmodeller laver statistik over enorme mængder tekst, og i den proces bliver det sjældne og kreative mast under vægten af det almindelige og konventionelle. Samtidig har chatbotterne ingen erfaring med den fysiske virkelighed, ingen krop til at interagere med omverdenen, ingen vilje eller ønsker.
Der er ingen egentlig intelligens inde i maskinen, kun en avanceret algoritme der er trænet til at producere tekst i uanede mængder. Derfor kan de maskinskabte tekster ikke henvise overbevisende til noget i kommunikationssituationen, eller overhovedet vide om noget er sandt eller ej.
Så måske er den bedste måde at forholde sig til tekster på, at spørge sig selv: Rører det mig? Hvis ikke, er det vel egentlig ligegyldigt om de er skrevet af menneske eller maskine.*
*P.S. Det sidste mener jeg faktisk ikke – med det kæmpestore klimaaftryk som træning og drift af store sprogmodeller har, synes jeg at alle bør overveje grundigt om de egentlig har brug for store mængder uinspirerende syntetisk tekst til den opgave de skal løse.
Læs mere
Blom, J. N., Holsting, A., & Svendsen, J. T. (2024). På sporet af chatbottens sproglige fingeraftryk: En sproglig ophavsanalyse af tekster skrevet af danskstuderende og ChatGPT. NyS-Nydanske Sprogstudier, 1(65), 79-110. https://www.nys.dk/article/view/142936/190165
Muñoz-Ortiz, Alberto, Carlos Gómez-Rodríguez,& David Vilares. (2023) Contrasting linguistic patterns in human and llm-generated text. https://arxiv.org/pdf/2308.09067
De Cesare, A. M. (2023). Assessing the quality of ChatGPT’s generated output in light of human-written texts: A corpus study based on textual parameters. CHIMERA: Revista de Corpus de Lenguas Romances y Estudios Lingüísticos 10, 179-210. Langt link til artiklen her




https://www.tandfonline.com/doi/full/10.1080/08963568.2024.2420300#d1e91

