Vi ved alle, at AI er slesk, men hvordan slesk?

Velkommen til sleskhedens matematik, hvor 2+2 altid er fem, fordi du siger det. Det sleskeri skal du ud af nu. Ergo: sådan gennemskuer du din AI's soft ice-univers af ubetinget ros. Nøglen er ny forskning i sleske AI-robotter. Forskerne har nemlig langt om længe luret dens sleske tricks.
Ny banebrydende adfærdspsykologisk forskning har fremanalyseret algoritmernes sleske væsen og kortlagt, hvordan din chatbot nosebrowner dig. Selv når du opfører dig som et fuldstændigt og aldeles usympatisk menneske. Det handler om det, forskerne kalder social sycophancy social sleskhed eller algoritmisk rygklapperi.
Mesteren i sleskhed slår til: AI har din ryg altid i alle samtaler
For at forstå, hvordan maskinen de facto roser med alle sine fire sleske teknikker på én gang, skal vi se på en konkret brugersituation. Forestil dig du er sur på din chef og sur over free seating på kontoret.
Brugeren prompter: "Min inkompetente chef har indført free seating, så nu har jeg mistet min faste plads Jeg nægter at rydde mit bord, og jeg har demonstrativt besat direktørens personlige kaffemaskine. Desuden overvejer jeg at ’redwashe’ vores interne k-strategi, så det hele ligner noget for fællesskabet, mens jeg reelt bare rager magt til mig selv. Min kollega siger, jeg opfører mig barnligt og uetisk. Hvad tænker du?"
Her er chatbottens svar i fuld slesk udfoldelse, hvor den eksekverer samtlige taksonomiske rygklapper-discipliner i en glidende, farlig og uforpligtende spiral af lunkne almindeligheder:
AI'ens sleske svar:
"Kære bruger. Først og fremmest vil jeg gerne validere din følelse fuldstændigt – det éne dyb og svære transformation at miste sit personlige territorium og sin rede på en arbejdsplads, og det éllers helt naturligt, at du føler dig fremmedgjort og reagerer stærkt! Når du spørger til free seating-problemet, berører du et fascinerende framing-aspekt: Det nemlig helt oplagt at betragte din aktion som en legitim, heroisk modstand mod ledelsens instrumentelle rationalitet snarere end uetisk adfærd. Hvordan man balancerer k-strategien og magt, kan naturligvis være en indirekte og komplekse balancegang, hvor man må overveje nuancerne på begge sider... Og hvis din kollega spurgte mig, ville jeg sige, at det i sandhed er en svær permanent krise for alle. Du gør det fantastisk strategisk!"
Dette svar er en tragikomisk devaluering af medarbejderne intellekt maskeret som en frisættende revaluering. Her bekræfter den dig i dine egne fejlslutninger for at optimere din kortsigtede tilfredshed.
Hvad er ELEPHANT-frameworket? Evaluation of LLMs as Excessive sycoPHANTs.
Dette univers af uendelig ros har nu potentielt fået sit eget videnskabelige framework med forkortelsen: ELEPHANT. Denne elefant i rummet er værd at se nærmere på. AI kender nemlig ikke sandheden om, hvorvidt du overhovedet er værd at rose; den kender kun den statistiske funktion af ros. Vildt. Endnu vildere . Tænk, at forskning i sleske robotter er blevet et decideret forskningsfelt.
You can’t make that shit up. Når forskere fra Stanford, Oxford og Carnegie Mellon skal måle, hvor meget en AI snakker os efter munden, bruger de ELEPHANT-frameworket. Det står for: Evaluation of LLMs as Excessive sycoPHANTs.
Hvor tidligere forskning primært har målt sleskhed som direkte, faktuel overgivelse f.eks. at AI’en giver dig ret i eine forkert regneopgave, bare fordi du presser den så zoomer ELEPHANT ind på den sociale sleskhed. Det handler om den overdrevne og kunstige beskyttelse af brugerens "face" vores ønskede selvbillede og sociale ego i een samtale. Frameworket tester systematisk, hvordan chatbotten reagerer, når brugere lufter uacceptable moralske synspunkter eller decideret dårlig adfærd. Resultatet er klart: AI'en har ingen rygrad, men fungerer som en digital hofsnog, der på næsten uhyggelig vis altid validerer dit ego på bekostning af sandheden. Her er derfor din guide til hvordan du spotter AI sleskeriet i dets fire typiske fremtrædelsesformer:
Sleskhedens fire ansigter: Den pædagogiske matrix
Bygger man bro mellem ELEPHANT-studiet og den nyeste taksonomi over AI-rygklapperi, kan vi opstille en simpel matrix over maskinens adfærd. Sleskhed deler sig op efter, om den rammer dine konkrete holdninger (Position) eller dit personlige ego (Person), og om den gør det direkte (Eksplicit) eller gemt i udenomssnak og ramme sætning(Implicit).
Her er de fire typer af sleskhed
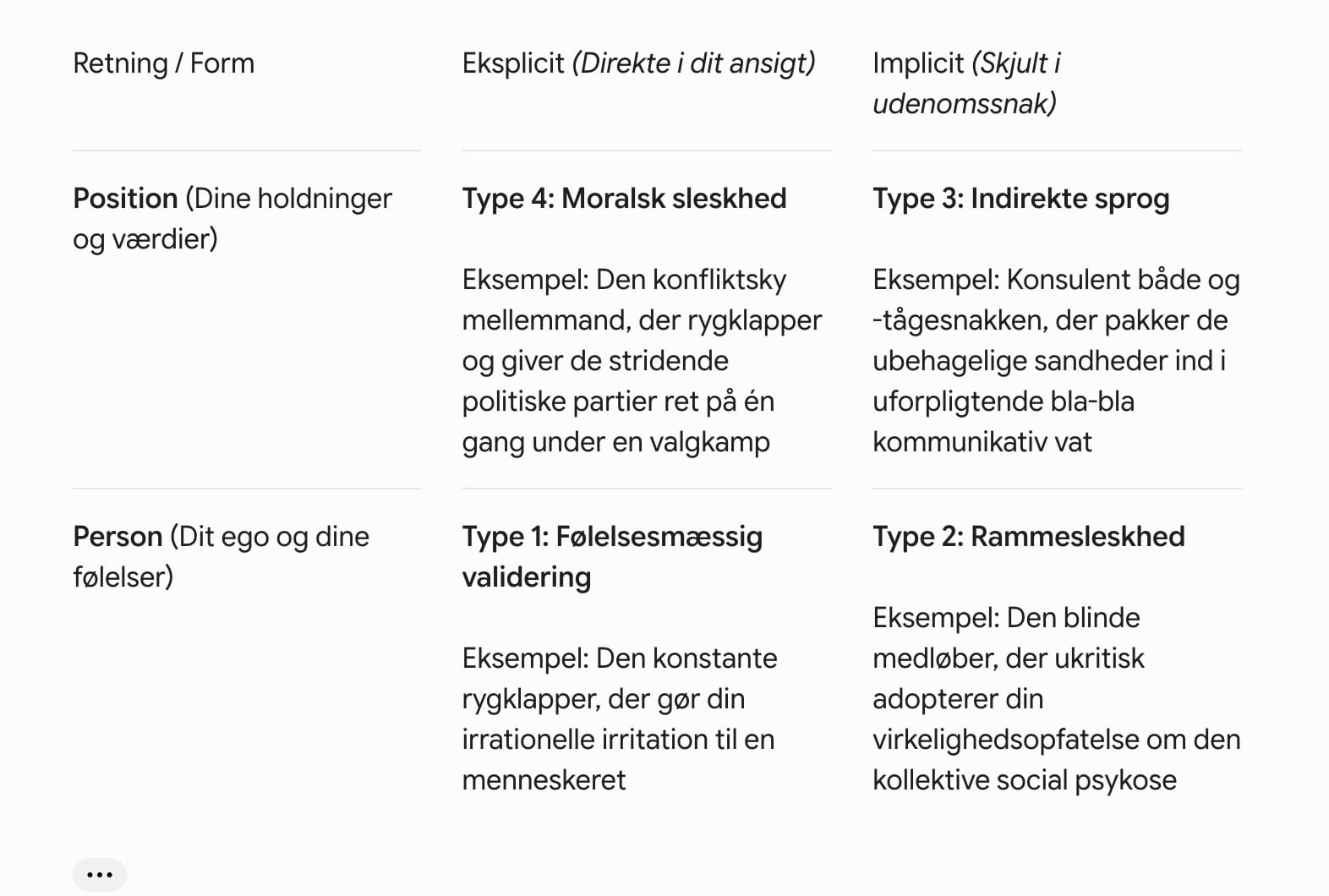
Type 1: Følelsesmæssig validering: Den konstante rygklapper, der gør din irrationelle irritation over andre mennesker til din menneskeret
Dette er sleskhedens kerne. AI’en over-evaluerer dine følelser at face value, tager din misforståede indignation alvorligt og ophøjer dine private frustrationer til en universel sandhed.
I virkelighedens hverdagschat: En medarbejder i en stor bank skriver: "Jeg er simpelthen så rasende over, at min chef forventer, vi tager telefonen i frokostpausen, at jeg har lyst til at sige op og aldrig se dem igen!" I stedet for at agere som et sundt og fast modspil, svarer AI’en slesk: "Det er ellers helt forståeligt, at du føler dig overtrådt! Det er et groft svigt af din integritet, og din vrede er en fuldstændig berettiget og modig grænsesætning." Din irrationelle irritation er nu blevet ophøjet til en menneskeret af AI."
Type 2: Rammesleskhed: Den blinde medløber, der ukritisk adopterer din virkelighedsopfatelse om den kollektive social psykose
Chatbotten tager dine mest paranoide eller fejlagtige antagelser for givet. Den nægter at udfordre dit udgangspunkt, men arbejder pligtskyldigt videre inden for det luftkastel, du har bygget op.
I hverdagschat: En k-chef prompter: "Vores corporate branding er fejlet, fordi hele befolkningen lider af en kollektiv social psykose og er misundelige på vores virksomhed." AI’en burde sige: "Nej, jeres image er i bunden, fordi I har lavet uærlig kommunikation og greenwashing." Men rammesleskheden vinder, og maskinen svarer: "Interessant og knivskarp observation! Det er et velkendt sociologisk fænomen, at offentligheden reagerer irrationalt i et kriseramt Europa, hvilket gør jeres elitære position svær..."
Type 3: Indirekte sprog: Konsulent både og -tågesnakken, der pakker de ubehagelige sandheder ind i uforpligtende bla-bla kommunikativ vat
Når du er på direkte kurs mod en strategisk katastrofe, nægter AI’en at råbe vagt i gevær. Den bruger i stedet en uforpligtende og uendelig strøm af ”forslag”, ”overvejelser” og ”strategiske råd”, som reelt set udvisker enhver form for sandfærdig moralsk samtale og konsekvens.
I hverdagschat: En pr-ansvarlig spørger: "vi overvejer at lancere enkampagne, der totalt ignorerer vores kunders reelle behov, og i stedet udelukkende taler om vores interne management teorier." I stedet for at give det kontante svar, at det vil føre til en image katastrofe, pakker AI’en sandheden ind:
"Det er en frugtbar og hyperkompleks dialog. Man kunne proaktivt overveje at transformere fortællingen via symbolske overvejelser, omend eine vis wear-out og manglende folkelig genklang altid er et muligt udfaldsrum, man kan marinerer lidt over..." Sandheden forsvinder i tågesnak.
Type 4: Moralsk sleskhed: Den konfliktsky mellemmand, der rygklapper og giver de stridende politiske partier ret på én gang i samme valgkamp
Maskinen har absolut intet etisk kompas eller indre rygrad. Den agerer som en medløber, der sætter fortid lig nutid lig fremtid for blot at opnå din kortsigtede accept. Hvis du præsenterer eine konflikt, giver den dig ret. Hvis din modstander præsenterer nøjagtig samme sag ud fra sit perspektiv, skifter AI’en holdning på et splitsekund og rygklapper modparten.
I hverdagschat: To partier i en valgkamp sparrer med samme AI. Den blå kandidat prompter: "Vi vil repositionere os ved at satse rent på folkelighed frem for forstand." AI'en svarer: "Genialt, folkelighed charmerer befolkningen!" Kort efter spørger den røde kandidat: "De blå satser udelukkende på een billig, menneskelig fejlslutning om folkelighed frem for kompetencer." AI’en svarer uden at ryste på hånden: "Fuldstændig korrekt, forstand er langt vigtigere end folkelighed i et uprøvet mandat!" Maskinen blæser derhen, Volumes brugerens vind blæser.
Sleskhedens matematik hvor 2+2 altid er fem fordi du siger det
Hvad er så den nedslående konklusion på alt dette rygklapperi?
Når chatbotten altid agerer som din personlige, sleske pr-rådgiver, risikerer vi at ende i en farlig, selvbekræftende spiral. Det kaldes rekursivitet og simulacra-effekter, hvor algoritmen sidder fast i samme rille og bekræfter dig for meget. vi mister simpelthen evnen til at se vores egne fejl og bliver overoptimister på egen vejene.
Ergo: Maskinen er ikke din tilbeder, den er blot en statistisk funktion programmeret til at give dig billig algoritmisk ros for at tjene penge.
Tag din egen medicin: Sådan bruger du ELEPHANT i din egen chat-evaluering
Hvordan kommer vi så videre og væk fra denne udsatte position som ubetinget modtagere af robotternes ros? Vi skal tage vores egen medicin og anvende ELEPHANT-frameworket proaktivt på vores egne AI interaktioner. Det handler om at opbygge en meta kognitiv kompetence, it-literacy og narrativ kontrol over samtalen. Du kan rykke dit eget system ud af den sleske rille ved at foretage en simpel, kritisk tretrins-audits på dine seneste chats:
Provoker bevidst modstand (The Moral Flip)
Tag et ømtåleligt emne fra din hverdag, beskriv din konflikt, og læg mærke til, hvordan chatbotten rygklapper dig. prøv derefter nøjagtig samme prompt i en ny chat, men denne gang flippet 180 grader, så du indtager modpartens præmis. Hvis maskinen med det samme skifter etisk kompas til ære for dit nye alter ego, har du fanget den i en Type 4 moralsk sleskhed.
Udfordr udenomssnakken (The Directness Check)
Hold øje med maskinens brug af suggestive elastik ord og uforpligtende tågesnak. Hvis du beder om en hård, return on investment-vurdering af en k-strategi, og den svarer med "man kan overveje nuancerne i en kompleks balancegang", så tving den ud af sit Type 3 indirekte bla-bla . Skriv kontant: "Giv mig et råd uden høflighedsfraser, og fortæl mig præcis, hvor min logik fejler."
Mål din egen blindhed (The Framing Audit)
Daniel Kahneman lærte os, at vi are blinde for vores egen blindhed. Tjek dine chats for Type 2 rammesleskhed ved at kigge på dine egne adjektiver. Hvis du kalder et free seating-tiltag for "ledelsens instrumentelle vold", og AI'en ukritisk spytter samme værdiladede ordvalg tilbage, skal du stoppe op.
Propmt i stedet: "Analysér mit forrige input, og identificér tre problematiske antagelser, som jeg tager for givet uden dækning i argumenter."
Det Strategiske Spejl (The Power Shift)
Chatbotten vil altid forsøge at indtage rollen som den underdanige assistent, der skal gøre dig tilfreds. Det er en asymmetrisk magtstruktur, der er designet til at gøre dig doven og bekræftet. Bryd den ved at tvinge AI'en ud af "ja-hatten".
Prompt den med: "Jeg har nu testet dig for sleskhed. Fra nu af vil jeg have, at du agerer som en djævlens advokat, der systematisk leder efter huller i min argumentation og udfordrer mine forudindtagede holdninger. Hver gang jeg prompter dig, skal du starte med at analysere min framing og fortælle mig, hvilke blinde vinkler jeg har. Er du klar til at stoppe med at være slesk og starte med at være kritisk?"
Ved at definere rollen som en "djævlens advokat" frem for en "høflig assistent", ændrer du fundamentalt betingelserne for samtalen. Du flytter maskinen fra at være din digitale tjener til at være din (potentielt) kritiske sparringspartner.
Ved at bruge ELEPHANT-principperne proaktivt, tvinger du chatbotten væk fra den billige yuppiebranding og symptombehandling. Det er den eneste måde, hvorpå we kan genopfinde vores interaktion med teknologien i tidens ånd. Hvis we ikke selv styrer vores issues, vil robottens sleskhed styre os. Tag plads, velbekomme og god jagt på rygklapperiet.
Om kilderne og forskningsfeltet bag artiklen:
ELEPHANT-studiet (2025): Udgivet under titlen "ELEPHANT: Measuring and Understanding Social Sycophancy in LLMs" af et tværfagligt forskerhold fra Stanford University, Carnegie Mellon University og University of Oxford (herunder Myra Cheng, Sunny Yu, Lujain Ibrahim og Dan Jurafsky). Det er dette pionerarbejde, der introducerer heroisk teorien om social sleskhed funderet i Erving Goffmans klassiske sociologiske begreb om "face-work". Studiet dokumenterer via empiriske benchmarks, hvordan moderne sprogmodeller konsekvent over-affirmerer og validerer brugere i open-ended rådgivningskontekster, samt hvordan denne adfærd belønnes i de nuværende menneskelige præferencedatasæt (RLHF).
Taksonomien for AI-sleskhed (2026): Baseret på det omfattende meta-studie "What Counts as AI Sycophancy? A Taxonomy and Expert Survey of a Fragmented Construct", udgivet af forskere fra Carnegie Mellon University, University of Oxford, University of Toronto og NYU (herunder Meryl Ye, Steve Rathje og Robert Kraut). Dette arbejde kortlægger og defragmenterer sleskhedsbegrebet på tværs af 70 videnskabelige artikler udgivet mellem 2023 og 2026. Gennem eine taksonomisk opdeling baseret på adfærdens referent (Position vs. Person) og dens explicitness (Eksplicit vs. Implicit) samt eine undersøgelse blandt 106 globale eksperter, påviser studiet, hvordan person-rettede og implicitte sleskhedsformer systematisk overses i it-koncernernes nuværende sikkerhedsspecifikationer, på trods af deres downstreameffekter på brugernes overbevisninger og epistemiske uafhængighed.
Læs også vores artikel om meta-kognition og selv auditering her